GPU 가속 병렬처리를 지원하는 빅데이터 플랫폼
.png)
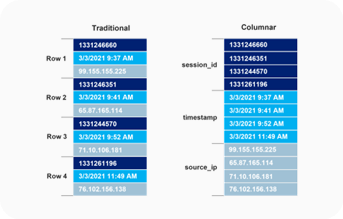
Columnar
- 공개된 Columnar Memory Format 기반 |
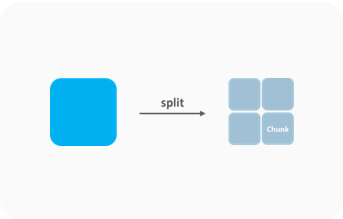
Chunking
- 컬럼화된 큰 데이터를 작은 Chunk 단위로 분리하여 저장 |
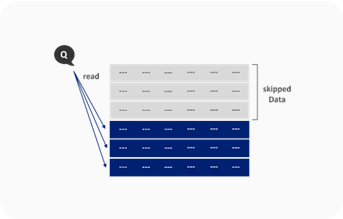
Metadata
- 기존 데이터베이스의 인덱스에 준하는 기능 |
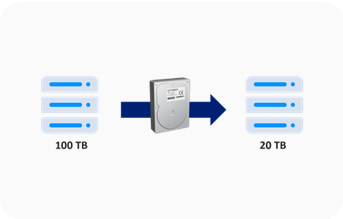
Compression
- 데이터 저장 시 데이터 성향에 맞추어 자동으로 압축 진행 |
Zero Copy
- 데이터를 네트워크로 전송할 때 발생하는 복사 과정 최소화 |
GPU Caching
- 데이터 저장 시 CPU 메모리와 GPU 메모리를 함께 활용 |