XDB supports unparalleled speed by supporting massive parallel processing based on SQL and GPU-accelerated operations. It uses the CPU and GPU together to deliver optimal performance and allows you to analyze all areas of complex and massive data. XDB is an ideal SQL engine for large data requiring high speed, and it will unlock deeper data value and business insight that could not be easily obtained before.

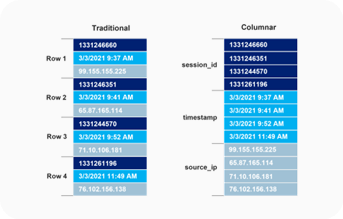
Columnar
- Based on open Columnar Memory Format |
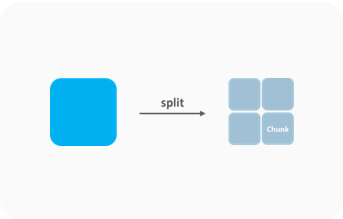
Chunking
- Separate and store large columnar data into small chunks |
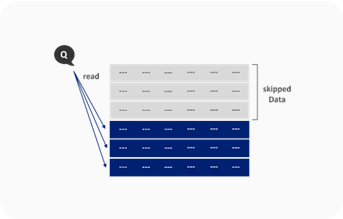
Metadata
- Functions equivalent to indexes in existing databases |
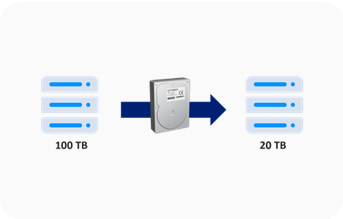
Compression
- When data is stored, it automatically compresses according to the data tendency |
Zero Copy
- Minimize the copy process that occurs when data is transferred over the network |
GPU Caching
- Utilizes CPU memory and GPU memory together for data storage |